idealstan: an R Package for Ideal Point Modeling with Stan
This is a paper that was presented at the StanCon2018 conference on Bayesian inference with the Stan Hamiltonian Markov Chain Monte Carlo (MCMC) method. Video of my talk is available here.
Introduction
This notebook introduces idealstan, a new R package front-end to Stan that allows for flexible modeling of a class of latent variable models known as ideal point models. Ideal point modeling is a form of dimension reduction, and shares similarities with multi-dimensional scaling, factor analysis and item-response theory. While the parameterization employed by idealstan is a derivation based on item-response theory, it is important to note that several other parameterizations are possible (Carroll, Lewis, Lo, Poole, and Rosenthal, 2013; Armstrong, Bakker, Carroll, Hare, Poole, and Rosenthal, 2014).
What distinguishes ideal point modeling from other latent space models is that the latent factor is bi-directional: in other words, the unobserved latent construct that underlies the data could increase or decrease as the observed stimuli either increase or decrease. This type of latent variable is very useful when the aim is to cluster units around a polarizing dimension, such as the left-right axis in politics or the \(p\)-value debate in statistics. While many of the applications of ideal point models are in political science and economics, it certainly can be applied more broadly, especially as the approach is related to latent space models more generally, such as in Hoff, Raftery, and Hancock (2002).
There are well-established frequentist (emIRT) and Bayesian (pscl and MCMCpack) packages for ideal point inference with R. However, these packages offer standard models that are limited in scope to particular problems, especially when it comes to including predictors in the latent space. The R package idealstan has three features that set it apart from existing approaches:
- Stan offers significant flexibility compared to existing approaches in using non-conjugate priors and a clearer programming interface. This flexibility allows for more options for end users in ideal point modeling that can be used to test new theories and hypotheses instead of being limited in the range and type of models available. In particular, Stan makes it easier to add hierarchical and time-series priors on to parameters, which opens the door to further analysis of dynamic and time-varying social phenomena.
- Stan scales well with the number of parameters, which is an attribute of most dimension reduction methods. Advances in Hamiltonian Monte Carlo estimation, including the use of variational inference and soon parallel computing within chains, promise to make full Bayesian inference of these models practical even with very large datasets.
- Increasingly, Stan is being married to helpful and powerful diagnostic packages, including
bayesplot,shinystanandloo, which extends the ability ofidealstanto provide not only cutting-edge Bayesian inference but also increasingly sophisticated tools for graphical analysis of resulting estimates. Given the complex nature of latent variable models, diagonistics are extremely important for determining when the model is behaving as it should (and what the model should be doing in the first place).
idealstan is an effort to build on prior efforts but also to offer new models that satisfy the increasing variety of applications to which ideal point models are being put. Both pscl and MCMCpack were designed for ideal point modeling of binary (logit) data from legislatures in which the outcome is made up of yes and no votes cast by legislators (Clinton, Jackman, and Rivers, 2004; Martin and Quinn, 2002). More recently scholars have begun applying ideal point models to Twitter data (Barberá, 2015), massive campaign finance datasets (Bonica, 2014) and party campaign manifestos (Slapin and Proksch, 2008). This package offers both the traditional forms of ideal point models along with new extensions, including a version of ideal points that can take into account certain forms of missing data.
In this notebook I first introduce ideal-point models and contrast them with “traditional” item response theory (IRT), and then I demonstrate the idealstan package through simulations. I then perform two empirical analyses, the first of coffee product ratings from Amazon and the second with voting data taken from the 114th Senate. In the second example, I also show how idealstan enables new estimation of strategic legislator absence, a type of data that is usually coded as missing in vote datasets.
Ideal Point Models as a Subset of Statistical Measurement
Measurement error models have a long history in applied statistics and are increasingly in demand as the amount of noisy observational data grows with the digital revolution. Canonical statistical models, particularly linear regression, assume that the predictors are measured without error, but in many situations in social science, the variable of interest cannot in fact be measured. Rather, proxies or indicators are used to stand in for the latent construct. Measurement models offer a way to match the indicators with the latent construct while making appropriate assumptions about the relationship.
In other words, we suppose that the regression predictor matrix \(X\) is itself a function of certain indicators \(I\_c \in \{1 ... C\}\):
\[ X = f(\forall I\_c \in \{1 ... C\}) \]
Different latent variable, latent space and measurement models can be distinguished in terms of the function \(f(\cdot)\). Fundamentally, \(f(\cdot)\) has to stipulate how \(X\) will change as the indicators change. It is possible to make very precise conditions for this relationship, which is the method applied in confirmatory factor analysis and structural equation modeling. It is also possible to let \(f(\cdot)\) make only minimal assumptions about this relationship, which is the method adopted by exploratory factor analysis and item-response theory (IRT), in addition to the other latent space models in the literature. It is also possible, of course, to have models that fall somewhere in between truly exploratory and truly confirmatory models.
While much has been written about the different kids of \(f(\cdot)\) that can be used in measurement models, in this paper I focus on a metric relevant to ideal point models: as the values of \(I\_c\) increase, does \(X\) also increase so that \(f(\cdot)\) must be always non-decreasing? If that is the case, then the model can be thought of as falling into the domain of item-response theory and traditional factor analysis (in fact, IRT is itself a non-linear version of factor analysis per Takane and de Leeuw (1986)). By contrast, ideal point models are based on a different set of assumptions in which \(X\) could increase or decrease as the indicators \(I\_c\) increase or decrease; in other words, the relationship is bi-polar instead of uni-polar.
Ideal point modeling originated from analysis of a common situation in policy research in which different legislators select from among competing policy alternatives based on the utility offered by each policy (Enelow and Hinich, 1984; Poole, Lewis, Lo, and Carroll, 2008). Supposing that the policies are evaluated on a uni-dimensional space, if the utility of the “Yes” position on the policy is greater than the utility of the “No” position to a particular legislator, then that legislator will choose that policy. While very simple, this model has a requirement that is different from much of traditional IRT estimation: the policy outcomes can have different meanings based on their position relative to the legislator in the policy space. For example, if a legislator is very liberal (has a high value on the latent construct), then that legislator is likely to vote yes on bills that are also liberal, such as single-payer health care. But if the bill is conservative, such as national defense, then that legislator is more likely to vote no. In other words, the meaning of the positions of the bills in the latent space depends on the ideal point of the legislator, and thus the mapping to the latent space \(f(\cdot)\) cannot be always non-decreasing. For some votes, a yes position may mean a high value of the latent space, while for others it may mean a lower value.
By comparison, in traditional IRT, responses to stimuli (the indicators \(I\_c\)) reflect correct or incorrect answers, such as a student taking a test. Correct answers, which in the legislative context mean yes votes, always equal greater ability, while incorrect answers, which would be no votes, are always a sign of less ability. In this situation, \(f(\cdot)\) is always non-decreasing. Thus while ideal point models share much in common with IRT, they require different assumptions.
A brief review of the mathematical notation will make the difference clear. The 2-PL IRT model takes the following form:
\[ Y\_{ij} = \alpha\_j x\_i - \beta\_j \]
where \(Y\_{ij}\) can be an outcome of any type (binary, ordinal, Poisson, etc.) that includes the correct or incorrect responses of \(I\) test takers to \(J\) test items, \(\alpha\_j\) are the discrimination parameters that control the narrowness, hence discrimination, of each item \(j\) on the test in the latent space, \(x\_i\) are the test-taker ability parameters that reflect the ability of a person to answer an item correctly, and \(\beta\_j\) are the difficulty or average probability/value of a correct response (the intercept). In the traditional IRT format, the \(\alpha\_j\) discrimination parameters are always positive because a higher value (a correct answer) is always associated with higher ability \(x\_i\), while a lower value (an incorrect answer) is associated with less ability.
However, if the requirement that the discrimination parameters \(\alpha\_j\) are positive is removed, then this model can also be used for ideal point modeling. For most applications, ideal-point modeling using IRT is built on the standard 2-PL model (Clinton, Jackman, and Rivers, 2004; Bafumi, Gelman, Park, and Kaplan, 2005), with one notable exception: the discrimination parameters must be un-constrained, while in traditional IRT the discrimination parameters are constrained to all be either positive or negative. Constraining discrimination parameters to be positive is also the approach taken in the edstan package, which offers the full range of standard IRT models using Stan.
Leaving the discrimination parameters un-consrained ensures that a higher or lower value of \(Y\_{ij}\) could be associated with either a “correct” or “incorrect” answer as is necessary in an ideal point model. This happens because the latent space in an ideal point model is fundamentally a Euclidean distance that is rotation-invariant. The following figure makes this clear by showing a version of an ideal point model in which the ideal point (ability parameter) \(x\_i\) is represented by a Normal distribution while the Yes and No points of a proposed policy are vertical lines.
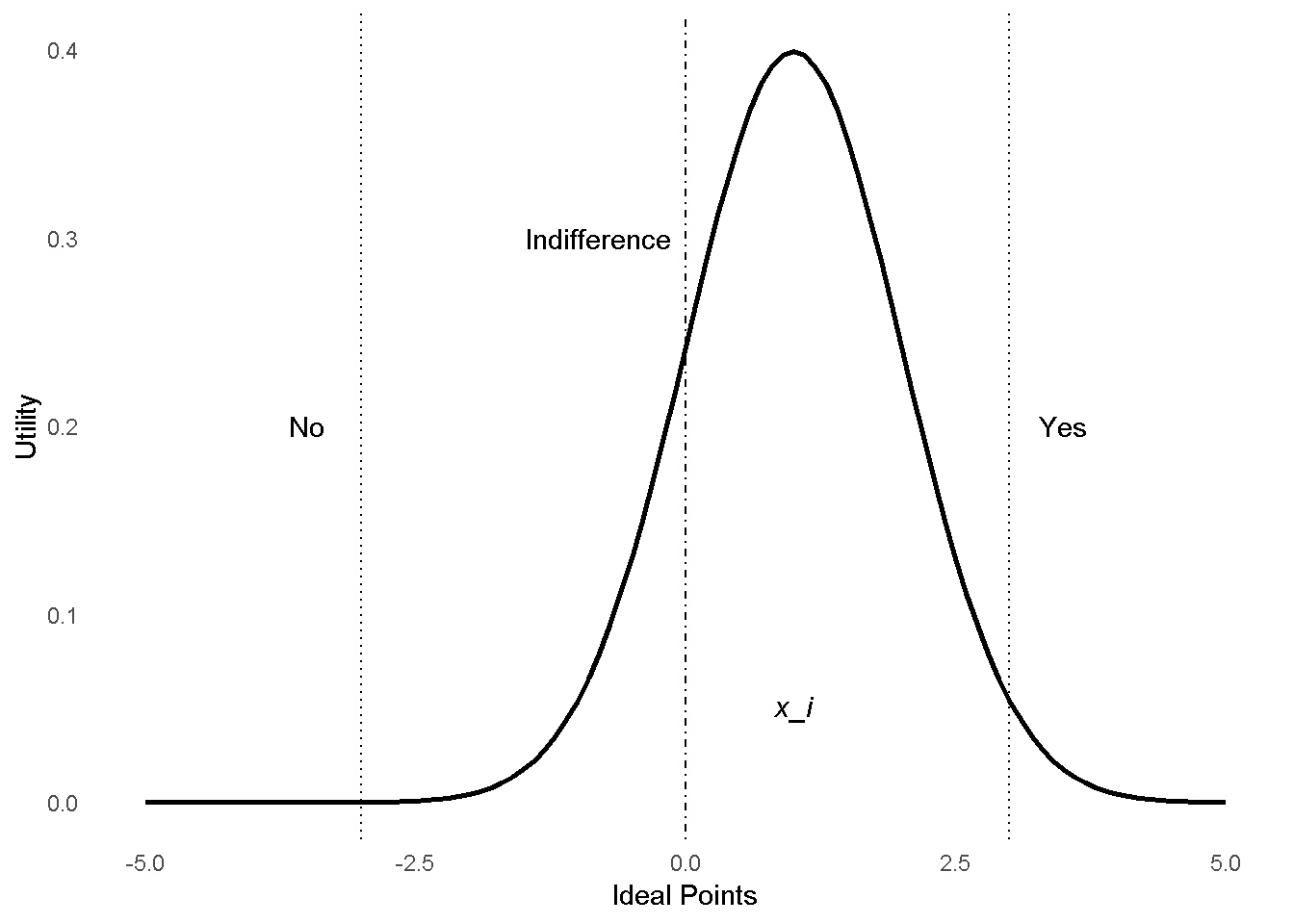
If \(x\_i\) is to the right of the Indifference line, the legislator will vote Yes on the proposal, whereas if she is to the left, she will vote No. However, a different policy (item) could have the Yes and No positions switched so that a Yes vote would correspond to -2.5 and vice versa for the No vote. Thus the binary outcomes do not have the same interpretation as the standard IRT model because the relationship between the outcomes and the ability points is contingent.
If the discrimination parameters are unconstrained, Clinton, Jackman, and Rivers (2004) showed that the midpoint of the policy/item parameter, which is labeled on the plot as the indifference line, is identified as \(-\frac{\alpha\_j}{\beta\_j}\) in the original IRT model. This midpoint is important because it represents the point in the latent space in which an actor is indifferent, or has a 50% chance of voting yes or no. Unfortunately, the IRT paramerization of the ideal point model does not return the actual Yes or No positions of a bill/item, but these midpoints are sufficient to characterize the position of the items in the latent space.
While this difference between ideal point models and standard IRT may seem trivial, it has serious consequences for modeling. The basic issue is the non-identifiability of the IRT model, which the switching polarity of the discrimination parameters only makes more difficult. Ultimately, it becomes necessary to constrain the polarity of some of the ability or discrimination parameters to identify the model. However, it is necessary to choose parameters which would avoid “splitting the likelihood”, such as constraining a legislator whose true ideal point is near zero (Bafumi, Gelman, Park, et al., 2005).
idealstan exploits variational Bayesian (VB) inference (Kucukelbir, Ranganath, Gelman, and Blei, 2015) to assist with finding parameters for identification. idealstan first estimates an IRT model with rotation-unidentified parameters, which is not a problem for a single VB run. Then idealstan can select those parameters which show the highest or lowest values, and these parameters are then constrained in terms of their polarity. This approach can quickly speed up the sometimes painful process of identifying a particular IRT ideal point model, although it is also possible to constrain parameters before estimation based on prior information.
Missing Data in Ideal Point Models
Because of the flexibility of Stan,idealstan is not limited to implementing the standard IRT ideal point model. One of the modifications it offers is a model that can account for one-way censoring in the data, or what is called an absence-inflated ideal point model (Kubinec, 2017a). This model was motivated by the application of ideal point models to legislatures in which legislator actions are more diverse than simply Yes or No votes. Legislators can also be absent on votes and in parliamentary systems as in Europe, abstentions are also common. Abstentions occur when a legislator votes on a policy but refuses to either vote Yes or No, resulting in a vote record of abstention that conventional models will treat as missing data. However, if these two additional vote outcomes–absent and abstention–are removed from the estimation by encoding them as missing data, then the additional information about legislator behavior present in this data is lost.
As a solution for abstentions, I proposed in Kubinec (2017a) to model abstentions as a middle category between yes and no votes by treating \(Y\_{ij}\) as an ordered logistic outcome \(Y\_{ijk}\) for \(k\) in three possible vote choices: \(\{1,2,3\}\) (no, abstain, yes).
While switching from a logit to an ordered logistic model is straightforward, modeling the censoring implied by legislator absences requires the estimation of additional parameters. To do so, I model absence as a binary outcome in a separate equation as a hurdle model. Intuitively, legislators only show up to vote if they are able to overcome the hurdle of being present. Because in an ideal point model we only want to estimate a single set of person parameters (ideal points), I include an additional set of item (bill) parameters in the hurdle component that signify the way in which being absent on a policy proposal is related to the ideological value of the legislation.
The result is a two-stage model that inflates the ideal points by the probability that a legislator is absent on a particular bill. To create this model, I first start again with the essential 2-PL IRT model except that it now allows for cutpoints \(c\_k\) for the \(K-1\) vote outcomes (yes, abstain, no) with \(\zeta(\cdot)\) representing the logit function:
\[ L(\beta,\alpha,x|Y\_{ijk}) = \prod\_{i-1}^{I} \prod\_{j=1}^{J} \begin{cases} 1 - \zeta(x\_{i}'\beta\_j - \alpha\_j - c\_1) & \text{if } K = 0 \\ \zeta(x\_{i}'\beta\_j - \alpha\_j - c\_{k-1}) - \zeta(x\_{i}'\beta\_j - \alpha\_j - c\_{k}) & \text{if } 0 < k < K, \text{ and} \\ \zeta(x\_{i}'\beta\_j - \alpha\_j - c\_{k-1}) - 0 & \text{if } k=K \end{cases} \]
Except for the addition of the vote cutpoints, this model is identical to the standard 2-PL IRT form, with ability parameters \(x\_i\), discriminations \(\beta\_j\), and difficulties \(a\_j\). The cutpoints carve up the latent space so that as ability rises or falls, the legislator becomes more likely to vote yes or no with abstention falling in between these two categories.
This ordered logit has to be embedded in the hurdle model to account for one-way censoring. Suppose that each legislator has a choice \(r \in \{0,1\}\) in which \(r=1\) if a legislator is absent and \(r=0\) otherwise. With this notation, the likelihood of the hurdle model takes the following form:
\[ L(\beta,\alpha,X,Q,\gamma,\omega|Y\_{k},Y\_{r}) = \prod\_{I}^{i=1} \prod\_{J}^{j=1} \begin{cases} \zeta(x\_{i}'\gamma\_j - \omega\_j ) & \text{if } r=0, \text{ and} \\ (1-\zeta({x\_{i}'\gamma\_j - \omega\_j}))L(\beta,\alpha,X|Y\_{k1}) & \text{if } r=1 \end{cases} \]
For the hurdle model to be able to affect the legislator ideal points, a separate IRT 2-PL model is included to predict the binary outcome of absence or presence. In this secondary model, the \(\gamma\_j\) discrimination and \(\omega\_j\) difficulty parameters represent the salience of a particular piece of legislation to an individual legislator \(x\_i\). Only if a bill clears the hurdle of salience will the legislator choose to vote on the legislation, i.e., reach the vote outcome model \(L(\beta,\alpha,X)\). This device allows for the ideal points \(x\_i\) to adjust for the fact that the decision of a legislator to show up to vote on a particular bill may be strategic instead of random. In addition, this model is more widely applicable to situations in which an ideal point model is employed and missing data may be a function of the persons’ ideal points.
Model Simulation
To identify the model, I placed \(N(0,1)\) parameters on the \(x\_i\) ideal points and additional polarity constraints on either the ideal points \(x\_i\) or the discrimination parameters \(\gamma\_j\) and \(\alpha\_j\). As a further restriction, I constrain one of the \(\beta\_j\) to equal zero. These are the standard set of restrictions included in idealstan, although the scales of parameters can be modified. The full set of priors is as follows:
\[ c\_k - c\_{k-1} \sim N(0,5)\\ \gamma\_j \sim N(0,2)\\ \omega\_j \sim N(0,5)\\ \beta\_j \sim N(0,2)\\ \alpha\_j \sim N(0,5)\\ x\_i \sim N(0,1) \]
The \(c\_k\) parameters are the cutpoints for the \(K-1\) ordinal outcomes. They are given a weakly informative prior on the differences between the cutpoints (see the prior help file in the Stan Development Github site). The rest of the priors are arbitrary as the scale of the latent variables is fixed only in the priors themselves.
To demonstrate the package, I first generate data from this data-generating process using a function id_sim_gen() built into idealstan:
In this matrix, the legislators (persons) are represented by the rows and the bills (items) by the columns. The ordinal vote outcomes are numbered 1 to 3 (1=No,2=Abstain,3=Yes) and 4 represents absence.
I can then take this simulated data and put it into the id_estimate function. I also use the true values of the legislator ideal points \(x\_i\) for polarity constraints in order to be able to return the “true” latent variables. The id_estimate function loads pre-compiled stan code a la rstantools and then returns an R object containing a compiled stan model.
true_legis <- ord_ideal_sim@simul_data$true_person
high_leg <- sort(true_legis,decreasing = T,index.return=T)
low_leg <- sort(true_legis,index.return=T)
ord_ideal_est <- id_estimate(idealdata=ord_ideal_sim,
model_type=4,
fixtype='constrained',
restrict_type='constrain_twoway',
restrict_ind_high = high_leg$ix[1:2],
restrict_ind_low=low_leg$ix[1:2],
refresh=500)For testing simulation results, the package contains a residual plot for looking at differences between true and estimated values which are stored in the R object:
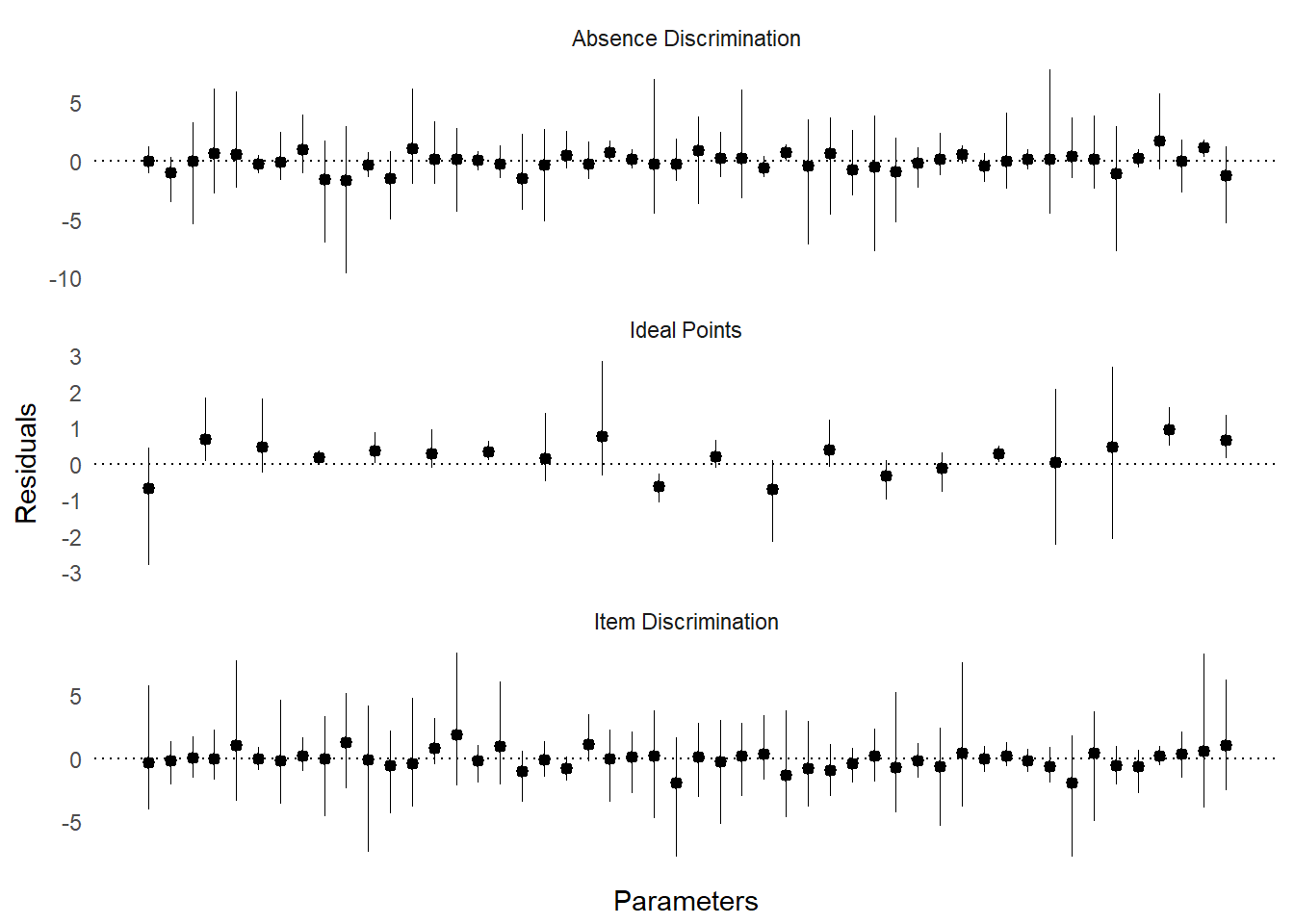
The recovery of the true parameters is not perfect, but generally the errors sum to zero across the parameters. Recovering the true parameters is not usually of great interest in a latent variable model as the scale and rotation of the true values is rather arbitrary. However, this exercise is a basic test of the Stan model’s correspondence with the simulated data.
Empirical Example: The Polarization of Coffee
To demonstrate the model’s functionality, I first use a dataset of ordinal rankings draw from Amazon food product reviews. McAuley and Leskovec (2013) collected over 500,000 Amazon food reviews from 1999 to 2012 which are all coded on the 1 to 5 ranking scale that users can post on each product. I focus on a subset of this data by collecting all the reviews that mention the word “coffee” at least a handful of times.
just_coffee <- readRDS('just_coffee.rds')Ideal point models use variation between products and users in reviews to identify the latent space. For these reasons, little information is contributed by products and/or users that have very few reviews, and we can remove them from the data first to reduce the dimensionality of the data. Because idealstan is a full Bayesian model, these users and products do not cause any statistical problems, but they will slow estimation considerably as a large number of users only review one or two products.
coffee_count_prod <- group_by(just_coffee,ProductId) %>% summarize(tot_unique=length(unique(UserId))) %>%
filter(tot_unique<30)
coffee_count_user <- group_by(just_coffee,UserId) %>% summarize(tot_unique=length(unique(ProductId))) %>%
filter(tot_unique<3)
just_coffee <- anti_join(just_coffee,coffee_count_prod,by='ProductId') %>%
anti_join(coffee_count_user,by='UserId')The data is currently in long format. To bring the data into idealstan, it first must be translated to wide format in which each item (product) is a column and each person (user) is a row. For this model, we will drop missing data as we will focus solely on the model’s ordinal rankings without accounting for the fact that users do not have reviews for all products.
Even with inactive users removed from the data, this model is quite large with 11269 users and 429 products. However, we can take advantage of variational inference in Stan to obtain approximate posterior estimates in a reasonable amount of time. We will also take advantage of idealstan’s use of variational inference for automatic model identification by running a non-identified (i.e., no constraints) model first, determining which of the users has a very high ideal point, and then constraining that ideal point in the final fitted model.
coffee_model <- id_estimate(idealdata=coffee_data,
model_type=3,
fixtype='vb',
restrict_ind_high = 1,
restrict_params='person',
auto_id = F,
use_vb=T)## ------------------------------------------------------------
## EXPERIMENTAL ALGORITHM:
## This procedure has not been thoroughly tested and may be unstable
## or buggy. The interface is subject to change.
## ------------------------------------------------------------
##
##
##
## Gradient evaluation took 0.042 seconds
## 1000 transitions using 10 leapfrog steps per transition would take 420 seconds.
## Adjust your expectations accordingly!
##
##
## Begin eta adaptation.
## Iteration: 1 / 250 [ 0%] (Adaptation)
## Iteration: 50 / 250 [ 20%] (Adaptation)
## Iteration: 100 / 250 [ 40%] (Adaptation)
## Iteration: 150 / 250 [ 60%] (Adaptation)
## Iteration: 200 / 250 [ 80%] (Adaptation)
## Success! Found best value [eta = 1] earlier than expected.
##
## Begin stochastic gradient ascent.
## iter ELBO delta_ELBO_mean delta_ELBO_med notes
## 100 -6e+004 1.000 1.000
## 200 -5e+004 0.642 1.000
## 300 -5e+004 0.441 0.284
## 400 -5e+004 0.346 0.284
## 500 -5e+004 0.277 0.059
## 600 -5e+004 0.234 0.059
## 700 -5e+004 0.200 0.040
## 800 -5e+004 0.176 0.040
## 900 -5e+004 0.157 0.014
## 1000 -5e+004 0.142 0.014
## 1100 -5e+004 0.042 0.006 MEDIAN ELBO CONVERGED
##
## Drawing a sample of size 1000 from the approximate posterior...
## COMPLETED.
## ------------------------------------------------------------
## EXPERIMENTAL ALGORITHM:
## This procedure has not been thoroughly tested and may be unstable
## or buggy. The interface is subject to change.
## ------------------------------------------------------------
##
##
##
## Gradient evaluation took 0.035 seconds
## 1000 transitions using 10 leapfrog steps per transition would take 350 seconds.
## Adjust your expectations accordingly!
##
##
## Begin eta adaptation.
## Iteration: 1 / 250 [ 0%] (Adaptation)
## Iteration: 50 / 250 [ 20%] (Adaptation)
## Iteration: 100 / 250 [ 40%] (Adaptation)
## Iteration: 150 / 250 [ 60%] (Adaptation)
## Iteration: 200 / 250 [ 80%] (Adaptation)
## Success! Found best value [eta = 1] earlier than expected.
##
## Begin stochastic gradient ascent.
## iter ELBO delta_ELBO_mean delta_ELBO_med notes
## 100 -5e+009 1.000 1.000
## 200 -1e+008 22.582 44.164
## 300 -9e+010 15.388 1.000
## 400 -4e+009 17.796 25.020
## 500 -2e+007 58.526 25.020
## 600 -2e+006 49.788 25.020
## 700 -1e+006 42.834 6.097
## 800 -5e+004 40.303 22.581
## 900 -5e+004 35.826 6.097
## 1000 -5e+004 32.244 6.097
## 1100 -5e+004 32.146 6.097 MAY BE DIVERGING... INSPECT ELBO
## 1200 -5e+004 27.730 1.114 MAY BE DIVERGING... INSPECT ELBO
## 1300 -5e+004 27.630 1.114 MAY BE DIVERGING... INSPECT ELBO
## 1400 -5e+004 25.128 0.016 MAY BE DIVERGING... INSPECT ELBO
## 1500 -5e+004 2.984 0.015 MAY BE DIVERGING... INSPECT ELBO
## 1600 -5e+004 2.374 0.005 MEDIAN ELBO CONVERGED MAY BE DIVERGING... INSPECT ELBO
##
## Drawing a sample of size 1000 from the approximate posterior...
## COMPLETED.What is of primary interest in this model are the discrimination parameters for the products. The discriminations will tell us which coffee products tend to divide the users most strongly into two poles as the model is one-dimensional. We can first look at the distribution of discriminations via a histogram:
id_plot_all_hist(coffee_model,params = 'regular_discrim')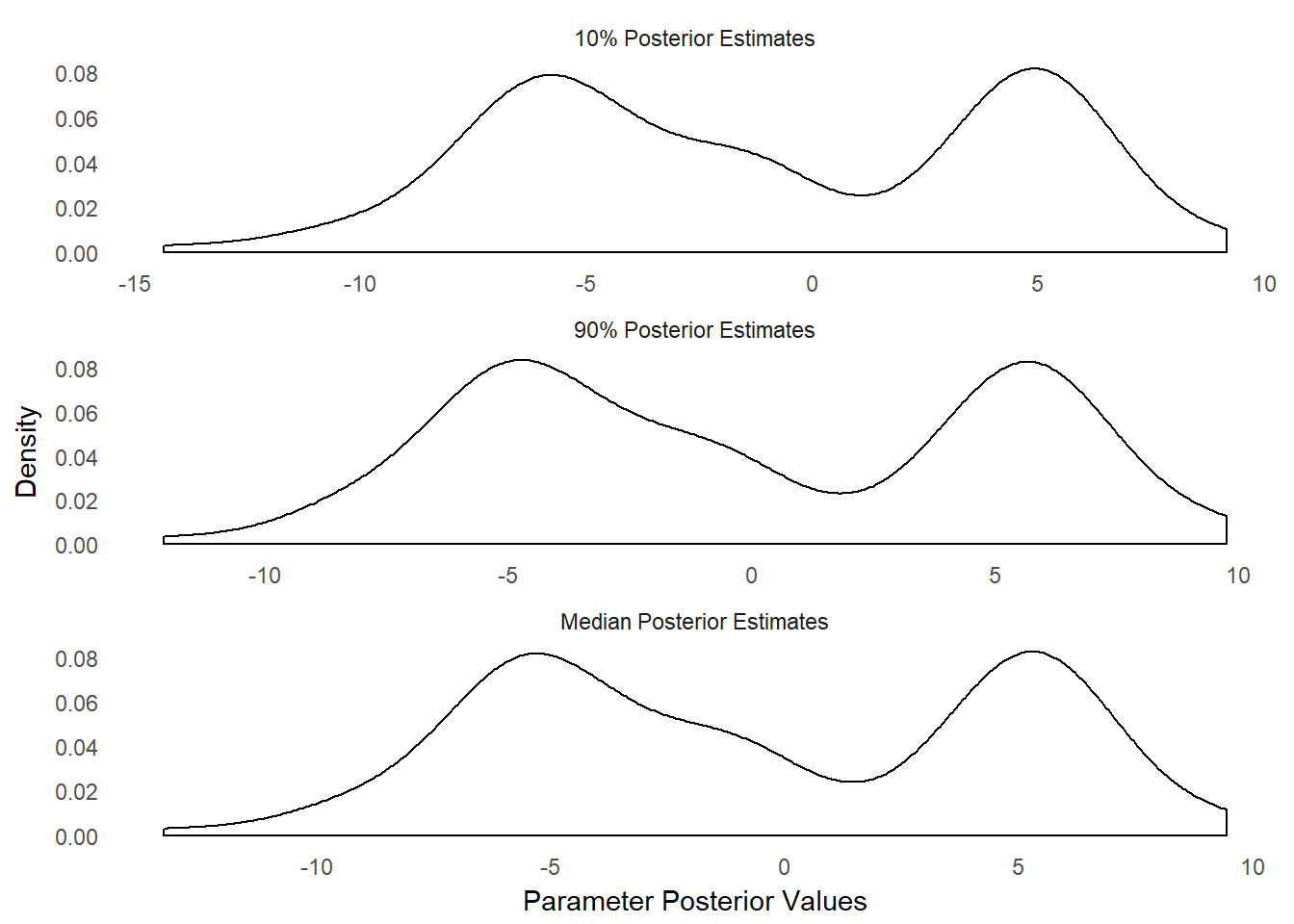
To gain a sense of how polarizing these products, we can plot the product mid-point, or the point at which a user is indifferent between one rating score and a higher rating score, over the ideal point distribution. I color the user points by their actual ratings:
id_plot_legis(coffee_model,group_color=F,group_overlap = T,
person_labels=F,person_ci_alpha = .05,
item_plot=429,
group_labels=F,
point_size=2,
show_score = c('1','2','3','4','5'),
text_size_group = 4)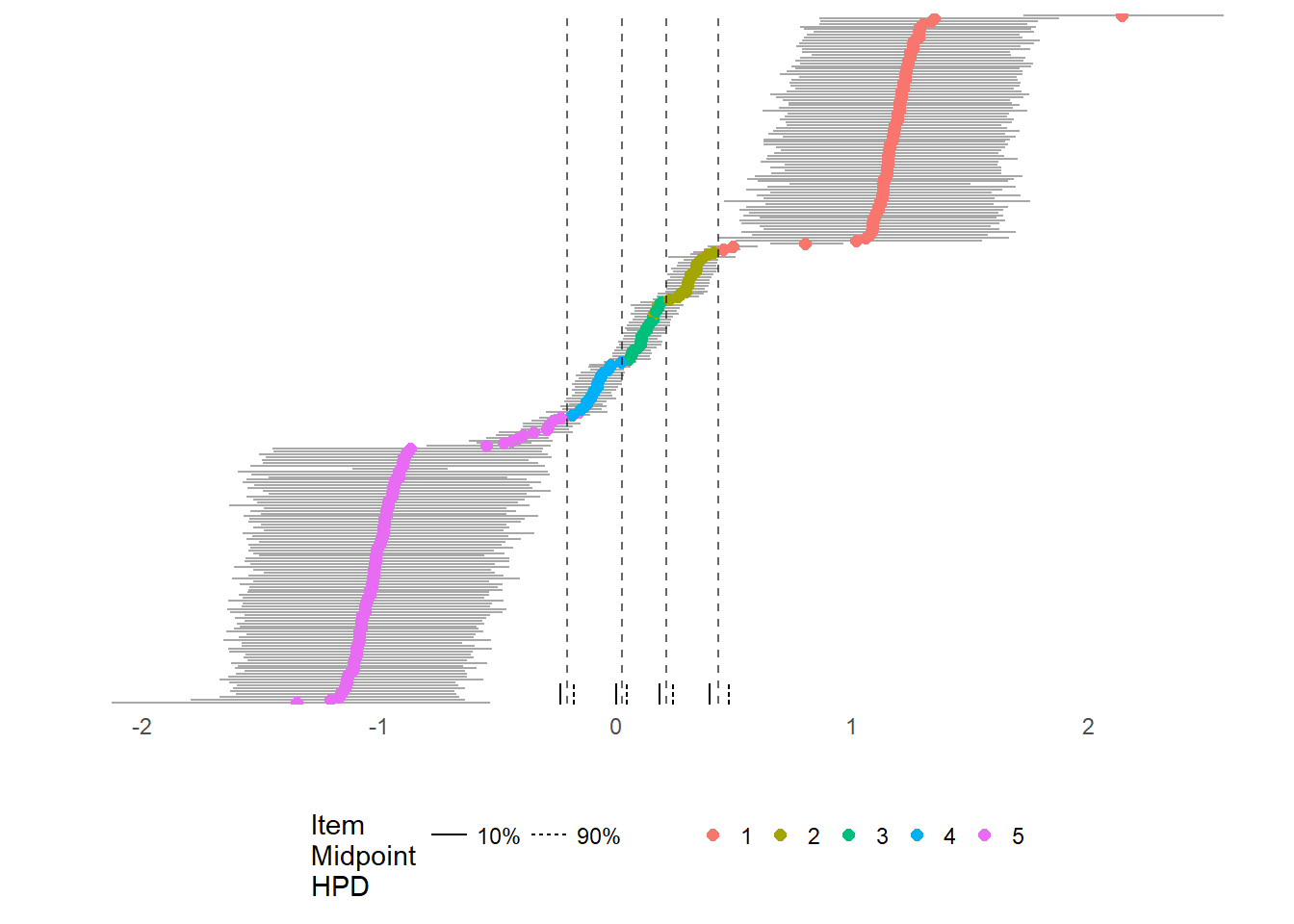
As can be seen, the product midpoints nearly perfectly segment the user base. We also a large number of 1s and 5s in the observed ratings. This distribution shows that users tend to be very divided on this product, and also that their disagreement over the product is itself a reflection of an underlying dimension, their ideal points.
Finally, I include here the top 10 most polarizing (highly discriminative) products from each end of the ideal point spectrum.
First, the top 10 most positive discrimination:
Second, the top 10 least positive negative discrimination:
While a full interpretation of these results would require significant work at examining the full range of products and their relevant discrimination scores, what is clear is that positive discrimination tends to have more large brands of coffee, including Starbucks and Illy, while the negative discrimination products tend to b esmaller brands, such as Melitta Cafe and Equal Exchange Organic Coffee. The most interesting finding in this analysis is that Ghirardelli products are at both ends of the scale: one type of Ghirardelli powdered drink, Ghirardelli Chocolate, has high positive discrimination, while Ghirardelli White Mocha has high negative discrimination. Intuitivelly, these products are appealing to different reviewers with very diverging preferences.
In the next section, I apply the ideal point model to a more traditional domain–the U.S. Congress–and also examine the role of including missing data via inflation.
Empirical Example: 114th Senate
As an empirical example of the model, I use data from the http://www.voteview.com website on the voting record of the 114th US Senate. This dataset comes with the idealstan package, and I then recode the data to correspond to a standard R matrix. However, because abstentions rarely happen in the US Congress, I do not include abstentions in this model and instead estimate a standard binary IRT 2-PL with inflation for missing data (absences). I then pass the matrix of vote records to the id_make function to create an object suitable for running the model.
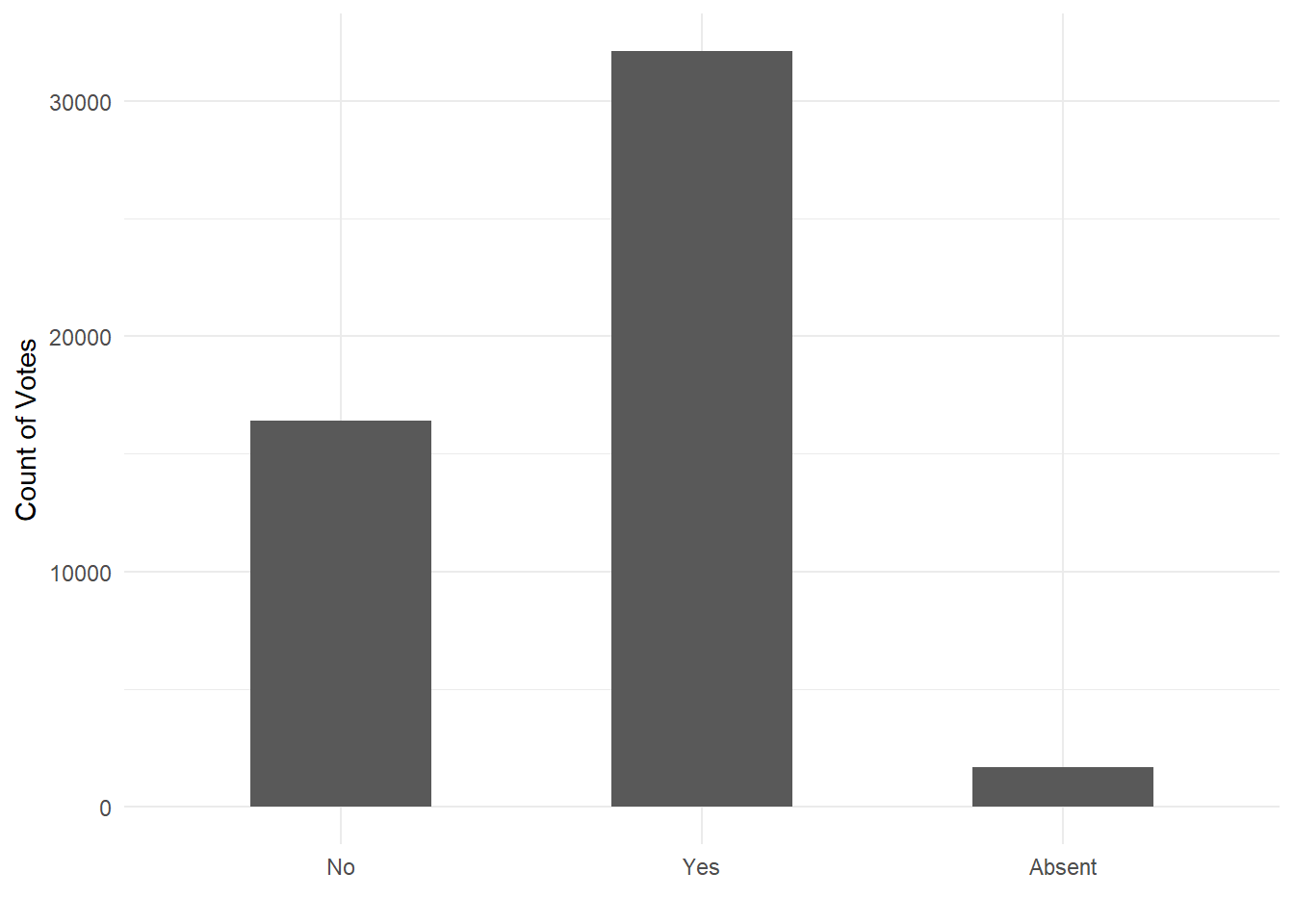
Given a suitable object from id_make, the id_estimate function can estimate a variety of IRT ideal point models, including 2-PL, ordinal, hierarchical and dynamic IRT (using random-walk priors). For this run we set the model_type parameter to 2, which represents a 2-PL model with absence inflation. Because this dataset is of a significant size, I use variational inference instead of the full sampler to demonstrate its use. I do not, however, use the automatic identification option auto_id because it is relatively easy to constrain particular legislator ideal points for the Senate. In this case, I constrain Ben Sasse, Marco Rubio, Berni Sanders, Ted Cruz, Harry Reid and Elizabeth Warren, all senators with pronounced ideological views.
After estimating the model, I can look at a graphical display of the ideal points with the id_plot function. The id_plot function produces a ggplot2 object which can be further modified. The legislators are given colors based on their party affiliation. The general shape of the ideal point distribution reflects the nature of polarization in the US Congress, with relatively few moderates near the center of the distribution.
## ------------------------------------------------------------
## EXPERIMENTAL ALGORITHM:
## This procedure has not been thoroughly tested and may be unstable
## or buggy. The interface is subject to change.
## ------------------------------------------------------------
##
##
##
## Gradient evaluation took 0.026 seconds
## 1000 transitions using 10 leapfrog steps per transition would take 260 seconds.
## Adjust your expectations accordingly!
##
##
## Begin eta adaptation.
## Iteration: 1 / 250 [ 0%] (Adaptation)
## Iteration: 50 / 250 [ 20%] (Adaptation)
## Iteration: 100 / 250 [ 40%] (Adaptation)
## Iteration: 150 / 250 [ 60%] (Adaptation)
## Iteration: 200 / 250 [ 80%] (Adaptation)
## Success! Found best value [eta = 1] earlier than expected.
##
## Begin stochastic gradient ascent.
## iter ELBO delta_ELBO_mean delta_ELBO_med notes
## 100 -2e+004 1.000 1.000
## 200 -2e+004 0.509 1.000
## 300 -2e+004 0.341 0.018
## 400 -2e+004 0.256 0.018
## 500 -2e+004 0.205 0.003 MEDIAN ELBO CONVERGED
##
## Drawing a sample of size 1000 from the approximate posterior...
## COMPLETED.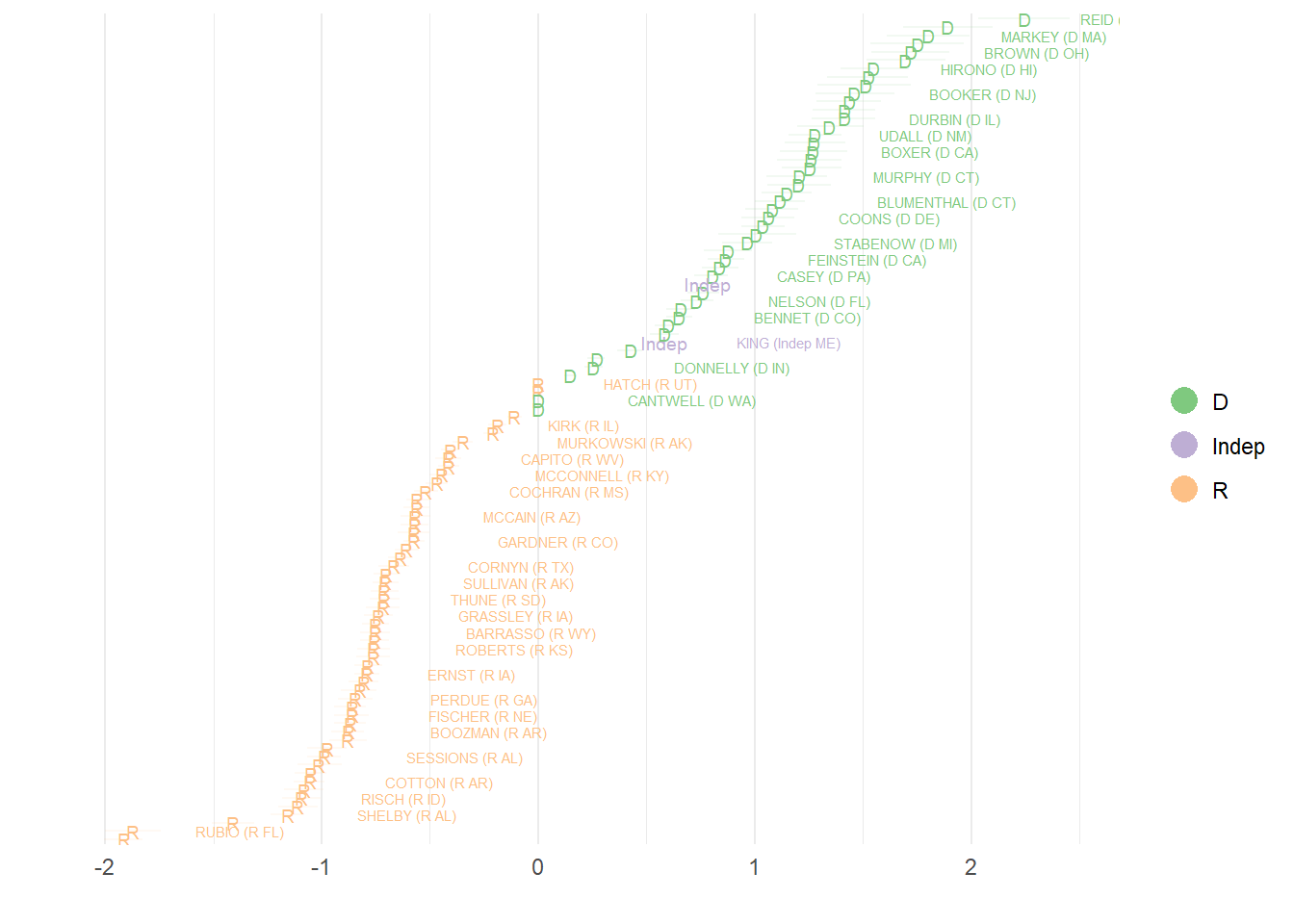
We can also plot the bill (item) midpoints as a line of indifference that we overlay on top of the ideal points.
id_plot(sen_est,person_ci_alpha=.1,item_plot=205,
group_labels=T,
abs_and_reg='Vote Points') + scale_colour_brewer(type='qual')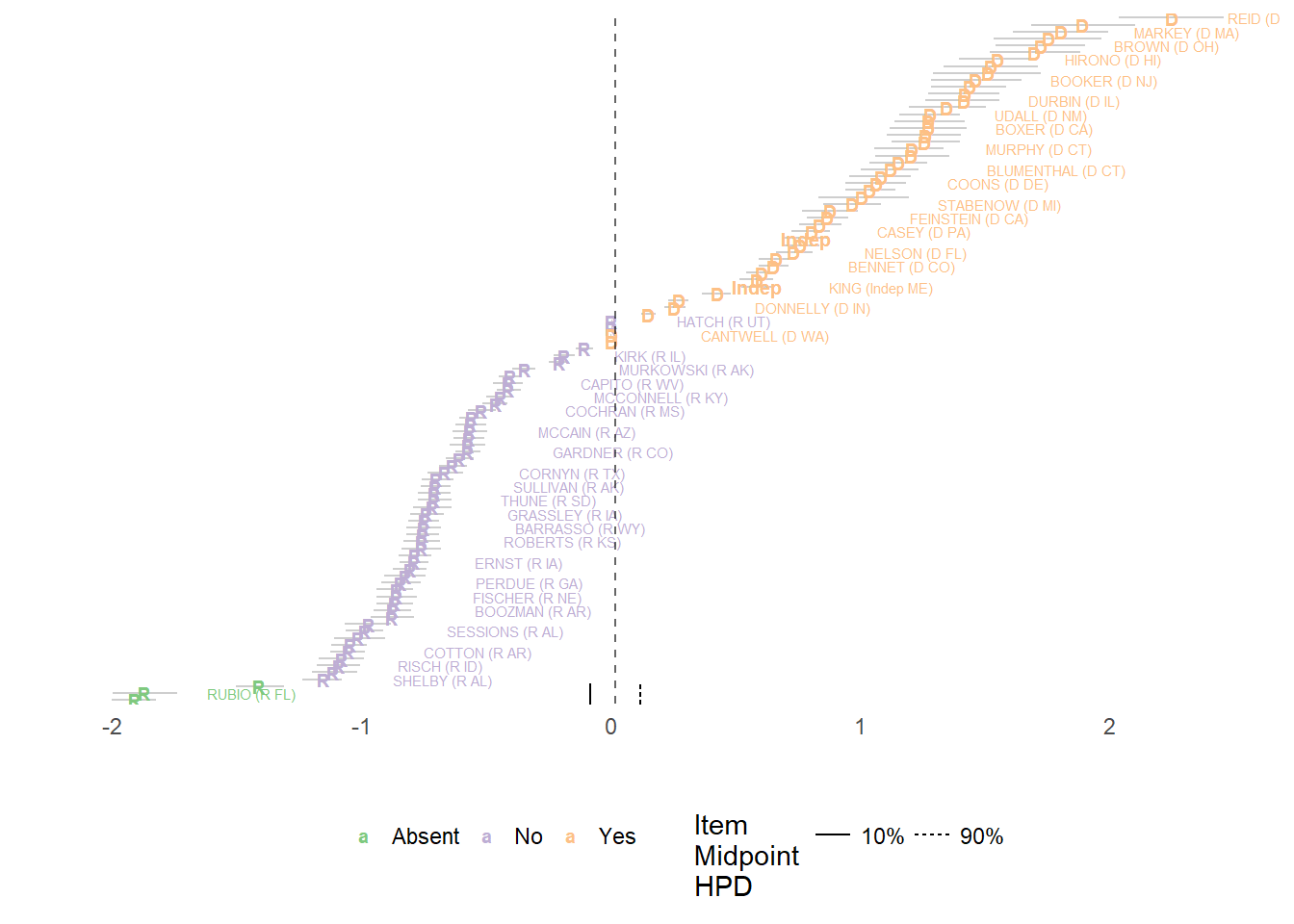
For this particular piece of legislation, the midpoint is right in the middle of the ideal point distribution, showing that the bill has very high discrimination. Also, the rug lines at the bottom of the plot, which show the HPD for the midpoint, indicate that the model is uncertain about the votes of only a handful of Senators on this bill.
We can similarly examine the absence midpoint for the same bill, which signifies the place on the ideal point spectrum at which a legislator is indifferent from showing up to vote. In this case, only very conservative Republicans chose not to show up to vote.
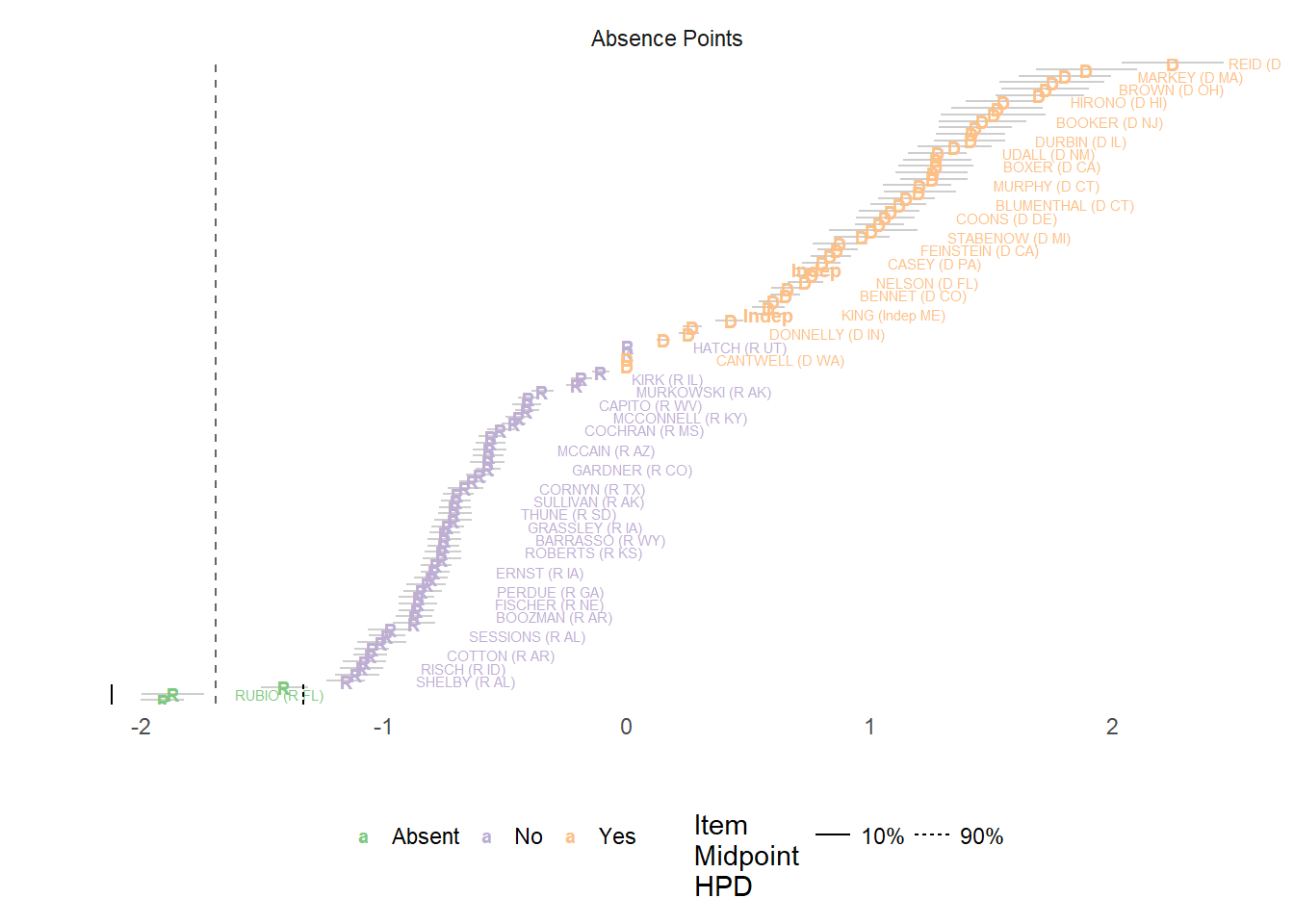
We can use the bill absence parameters to also see which bills showed the highest discrimination in terms of absences, or in other words, for which bills did the absence of legislators signify that they intentionally did not show up? To do this, I sort the discrimination parameters from the underlying Stan object and then merge them with the bill labels from voteview.org.
First we can look at the top 10 bills with liberal/Democrat absence discrimination:
Interestingly, Democrats appeared to be strategically absent most often on bills about climate change and the Keystone XL pipeline.
For conseratives the bills are as follows:
For Republicans, on the other hand, it appears that cybersecurity and inter-departmental information sharing were the laws in which they chose not to show up for ideological (or political) reasons. This could be due to concerns among the conservative base regarding government over-reach and collecting information.
Conclusion
idealstan is an effort to put state-of-the-art ideal point models along with the power of full Bayesian analysis in the hands of applied researchers in the social sciences. While the empirical examples presented were from the US Congress, the model can be used in any situation in which the assumptions of the ideal point model (unconstrained ideal point space) apply, i.e., situations in which the latent space is fundamentally polarizing between people. While similar in function and form to the edstan package, the idealstan package has to use more complicated forms of identification because of the difficulty of leaving discrimination parameters unconstrained.
Moving forward, I intend to add in more functionality to smoothly operate with shinystan and bayesplot, as well as add further types of explanatory IRT models. The intention is to have a package on which applied researchers can run different ideal point models and then examine how different modeling choices affect the results. In addition, I will continue to build more visualization options so that the results are easily digestable and publishable.
References
’ [1] J. M. Enelow and M. J. Hinich. The Spatial Theory of Voting: An Introduction. Cambridge University Press, 1984.
[2] Y. Takane and J. de Leeuw. “On the Relationship Between Item Response Theory and Factor Analysis of Discretized Variables”. In: Psychometrika 52.3 (1986), pp. 393-408.
[3] P. D. Hoff, A. E. Raftery and M. S. Hancock. “Latent Space Approaches to Social Network Analysis”. In: Journal of the American Statistical Association 97.460 (2002), pp. 1090-1098.
[4] A. D. Martin and K. M. Quinn. “Dynamic Ideal Point Estimation via Markov Chain Monte Carlo for the U.S. Supreme Court, 1953-1999”. In: Political Analysis 10.2 (2002), pp. 134-153.
[5] J. Clinton, S. Jackman and D. Rivers. “The Statistical Analysis of Rollcall Data”. In: American Political Science Review 98.2 (2004), pp. 355-370.
[6] J. Bafumi, A. Gelman, D. K. Park, et al. “Practical Issues in Implementing and Understanding Bayesian Ideal Point Estimation”. In: Political Analysis 13.2 (2005), pp. 171-187.
[7] K. T. Poole, J. B. Lewis, J. Lo, et al. Scaling Roll Call Votes with W-NOMINATE in R. Working Paper. Social Science Research Network, Oct. 06, 2008. URL: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=1276082.
[8] J. B. Slapin and S. Proksch. “A Scaling Model for Estimating Time-Series Party Positions from Texts”. In: American Journal of Political Science 52.3 (2008), pp. 705-722.
[9] R. Carroll, J. B. Lewis, J. Lo, et al. “The Structure of Utility in Spatial Models of Voting”. In: American Journal of Political Science 57.4 (2013), pp. 1008-1028.
[10] J. McAuley and J. Leskovec. “From Amateurs to Connoisseurs: Modeling the Evolution of User Expertise through Online Reviews”. In: WWW (2013).
[11] D. A. Armstrong, R. Bakker, R. Carroll, et al. Analyzing Spatial Models of Choice and Judgment with R. CRC Press, 2014.
[12] A. Bonica. “Mapping the Ideological Marketplace”. In: American Journal of Political Science 58.2 (2014), pp. 367-386.
[13] P. Barberá. “Birds of the Same Feather Tweet Together: Bayesian Ideal Point Estimation Using Twitter Data”. In: Political Analysis 23 (2015), pp. 76-91.
[14] A. Kucukelbir, R. Ranganath, A. Gelman, et al. “Automatic Variational Inference in Stan”. In: Advances in Neural Information Processing Systems 28. Ed. by C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama and R. Garnett. Curran Associates, Inc., 2015, pp. 568-576. URL: http://papers.nips.cc/paper/5758-automatic-variational-inference-in-stan.pdf.
[15] R. Kubinec. Absence Makes the Ideal Points Sharper. Poster. Political Methodology Society, 2017.
Robert Kubinec
Assistant Professor of Political Science
My research centers on political-economic issues such as corruption, economic development, and business-state relations in developing countries, and in particular the Middle East and North Africa. I am also involved in the development of Bayesian statistical models with Stan for hard-to-study subjects like corruption, polarization, and other latent social constructs.